728x90
12.1 정렬이란?
- 오름차순이나 내림차순으로 나열하는 것
12.2 선택 정렬
- 리스트 초기 상태
- 왼쪽 리스트: 비어있는 상태로 존재
- 오른쪽 리스트: 정렬되지 않은 숫자들이 들어 있다.
- 오른쪽 리스트에서 가장 작은 숫자를 선택하여 왼쪽 리스트로 이동하는 작업을 반복
- 오른쪽 리스트가 공백 상태가 되면 종료
➡️ 위 방법은 별도의 공간이 필요하다. 따라서 추가적인 메모리가 필요없는 제자리 정렬을 사용
제자리 정렬(선택 정렬)

더보기
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 10
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
int list[MAX_SIZE];
int n;
void selection_sort(int list[], int n)
{
int i, j, least, temp;
for (i = 0; i < n - 1; i++) {
least = i;
for (j = i + 1; j < n; j++) // 최소값 탐색
if (list[j] < list[least]) least = j;
SWAP(list[i], list[least], temp);
}
}
//
int main(void)
{
int i;
n = MAX_SIZE;
srand(time(NULL));
for (i = 0; i<n; i++) // 난수 생성 및 출력
list[i] = rand() % 100; // 난수 발생 범위 0~99
selection_sort(list, n); // 선택정렬 호출
for (i = 0; i<n; i++)
printf("%d ", list[i]);
printf("\n");
return 0;
}12.3 삽입 정렬
- 정렬되어 있는 리스트에 새로운 레코드를 적절한 위치에 삽입하는 과정을 반복한다.

// 삽입정렬
void insertion_sort(int list[], int n)
{
int i, j, key;
for (i = 1; i<n; i++) {
key = list[i];
for (j = i - 1; j >= 0 && list[j]>key; j--)
list[j + 1] = list[j]; /* 레코드의 오른쪽 이동 */
list[j + 1] = key;
}
}
12.4 버블 정렬
- 인접한 2개의 레코드를 비교하여 크기가 순서대로 되어 있지 않으면 서로 교환하는 비교-교환 과정을 0번 인덱스부터 차례로 진행한다.
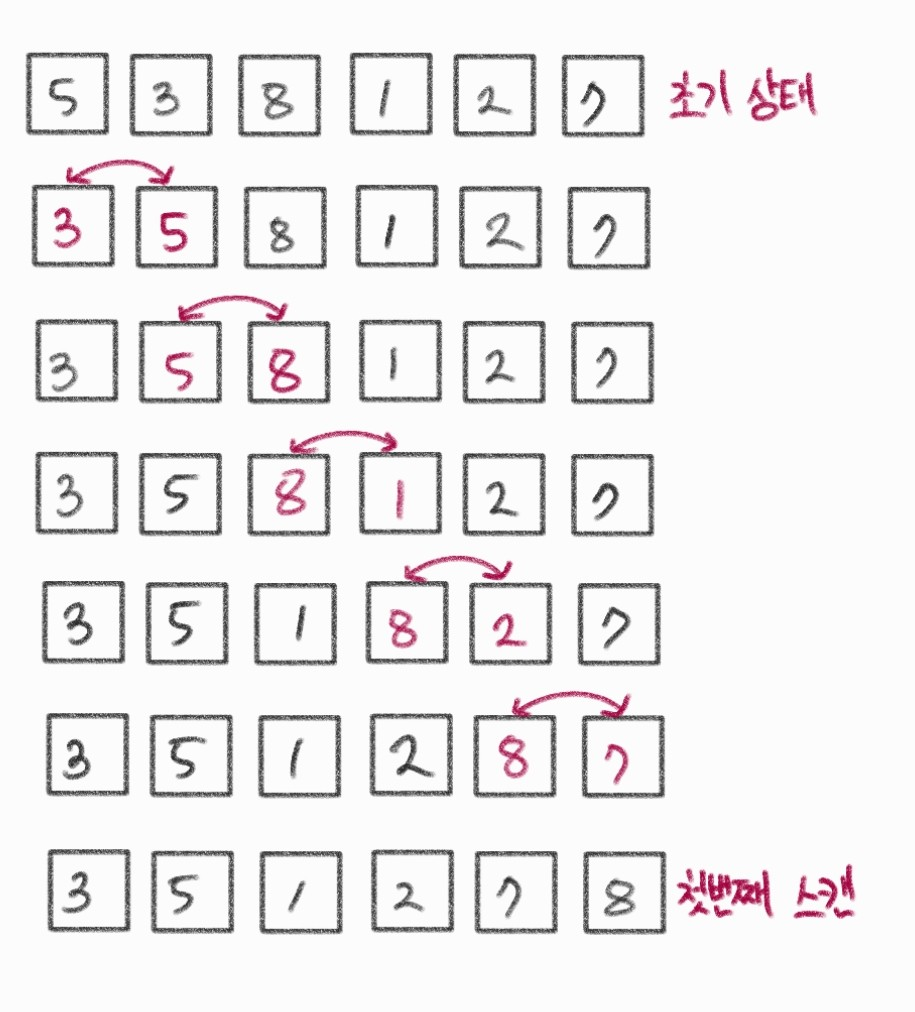
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) )
void bubble_sort(int list[], int n)
{
int i, j, temp;
for (i = n - 1; i>0; i--) {
for (j = 0; j<i; j++)
/* 앞뒤의 레코드를 비교한 후 교체 */
if (list[j]>list[j + 1])
SWAP(list[j], list[j + 1], temp);
}
}
12.5 쉘 정렬
- 삽입 정렬의 문제를 보완
- 요소가 삽입될 때, 이웃한 위치로만 이동
- 삽입될 위치가 현재 위치에서 멀리 떨어진 곳이면 많은 이동을 해야 제자리로 갈 수 있다.
- 정렬할 리스트를 일정한 기준에 따라 분류하여 연속적이지 않은 여러 개의 부분 리스트를 만들고, 각 부분 리스트를 삽입 정렬을 이용하여 정렬한다.

- 간격(k)의 초깃값은 정렬할 값의 수/2
- 생성된 부분리스트 수: k(gap)

- 각 회전마다 k를 절반으로 줄인다.
- k는 홀수
- k/2가 짝수면 k+1을 한다.
- k=1이 될때까지 반복한다.
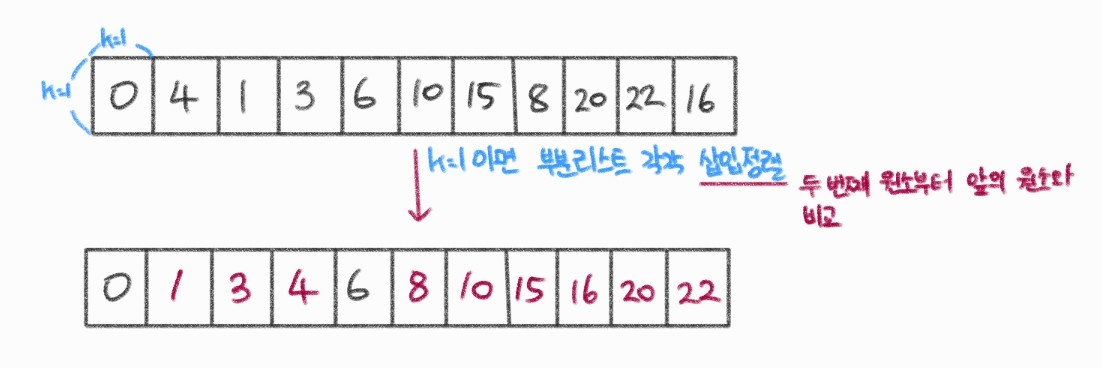
- k=1이면 부분리스트 각각 삽입 정렬을 진행한다.
// gap 만큼 떨어진 요소들을 삽입 정렬
// 정렬의 범위는 first에서 last
inc_insertion_sort(int list[], int first, int last, int gap)
{
int i, j, key;
for (i = first + gap; i <= last; i = i + gap) {
key = list[i];
for (j = i - gap; j >= first && key<list[j]; j = j - gap)
list[j + gap] = list[j];
list[j + gap] = key;
}
}
//
void shell_sort(int list[], int n) // n = size
{
int i, gap;
for (gap = n / 2; gap>0; gap = gap / 2) {
if ((gap % 2) == 0) gap++;
for (i = 0; i<gap; i++) // 부분 리스트의 개수는 gap
inc_insertion_sort(list, i, n - 1, gap);
}
}
쉘 정렬 과정
- 정렬할 리스트를 일정한 기준에 따라 분류
- 연속적이지 않은 여러 개의 부분 리스트를 생성
- 각 부분 리스트를 삽입 정렬을 이용하여 정렬
- 모든 부분 리스트가 정렬되면 다시 전체 리스트를 더 작은 개수의 부분 리스트로 만든다
- 위 과정을 반복
- 부분 리스트의 개수가 1이 되면 삽입 정렬을 진행
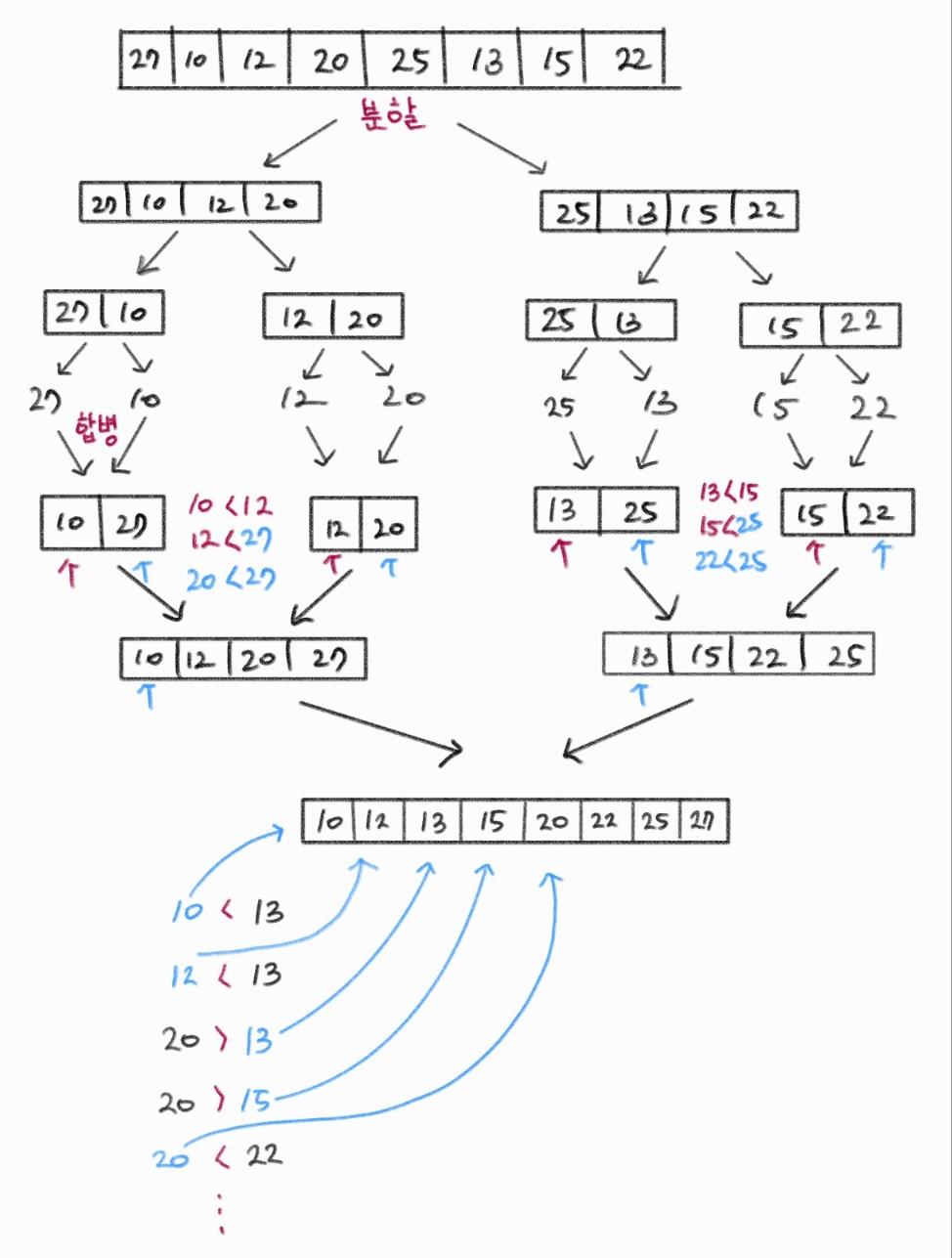
12.6 합병 정렬
- 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬하고 다시 합병하는 정렬
int sorted[MAX_SIZE]; // 추가 공간이 필요
/* i는 정렬된 왼쪽 리스트에 대한 인덱스
j는 정렬된 오른쪽 리스트에 대한 인덱스
k는 정렬될 리스트에 대한 인덱스 */
void merge(int list[], int left, int mid, int right)
{
int i, j, k, l;
i = left; j = mid + 1; k = left;
/* 분할 정렬된 list의 합병 */
while (i <= mid && j <= right) {
if (list[i] <= list[j])
sorted[k++] = list[i++];
else
sorted[k++] = list[j++];
}
if (i>mid) /* 남아 있는 레코드의 일괄 복사 */
for (l = j; l <= right; l++)
sorted[k++] = list[l];
else /* 남아 있는 레코드의 일괄 복사 */
for (l = i; l <= mid; l++)
sorted[k++] = list[l];
/* 배열 sorted[]의 리스트를 배열 list[]로 재복사 */
for (l = left; l <= right; l++)
list[l] = sorted[l];
}
//
void merge_sort(int list[], int left, int right)
{
int mid;
if (left<right) {
mid = (left + right) / 2; /* 리스트의 균등 분할 */
merge_sort(list, left, mid); /* 부분 리스트 정렬 */
merge_sort(list, mid + 1, right); /* 부분 리스트 정렬 */
merge(list, left, mid, right); /* 합병 */
}
}
합병 정렬 과정
- 분할: 입력 배열을 같은 크기의 2개의 부분 배열로 분할
- 정복: 부분 배열을 정렬. 부분 배열의 크기가 충분히 작지 않으면 순환 호출을 이용하여 다시 분할
- 결합: 정렬된 부분 배열들을 하나의 배열에 통합
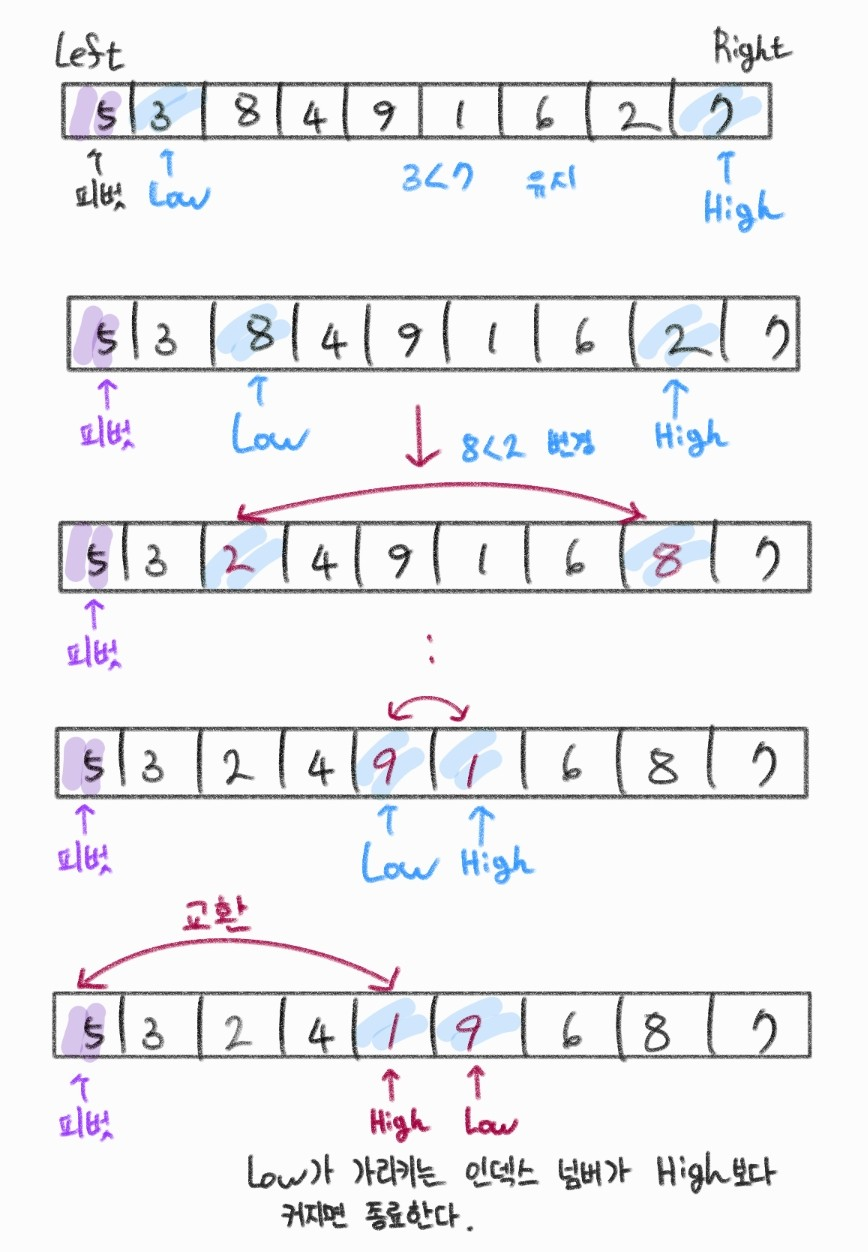
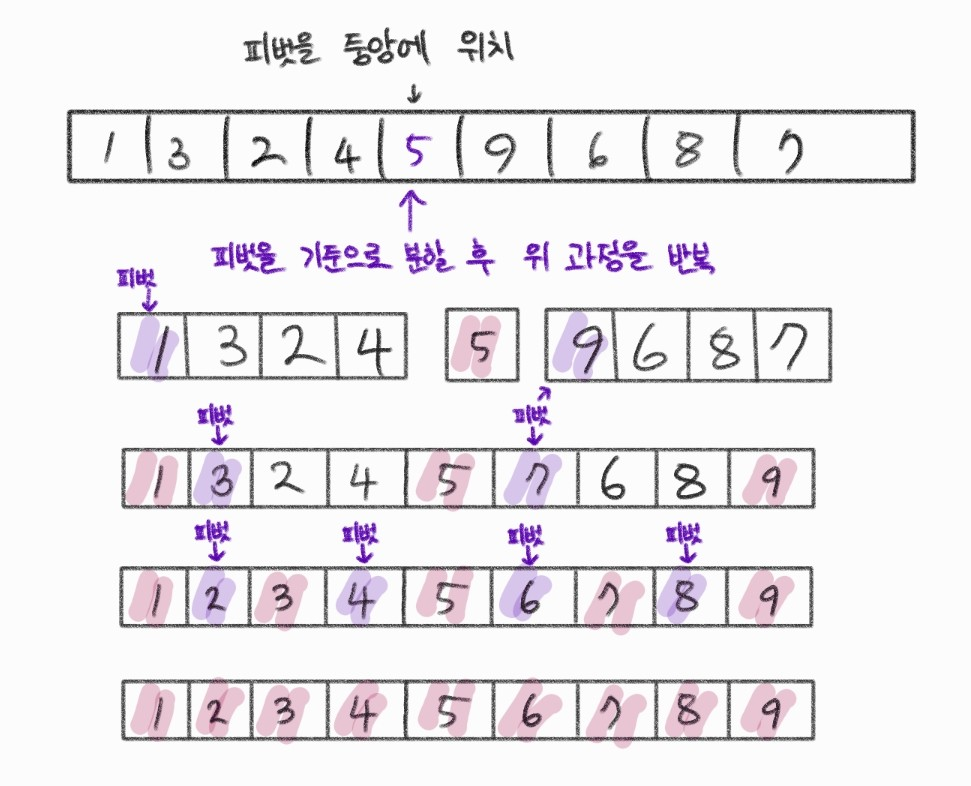
12.7 퀵 정렬
- 평균적으로 매우 빠르 수행 속도를 자랑하는 정렬방법
- 합병 정렬과 비슷하게 전체 리스트를 2개의 부분 리스트로 분할하고, 각각의 부분 리스트를 다시 퀵정렬한다.
- 피벗을 선정하여 피벗보다 작은 요소는 왼쪽, 큰 요소는 오른쪽으로 이동
더보기
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define MAX_SIZE 10 // 배열의 최대 크기
#define SWAP(x, y, t) ( (t)=(x), (x)=(y), (y)=(t) ) // 두 변수 값을 교환하는 매크로
int list[MAX_SIZE]; // 정렬할 배열
int n; // 배열 크기
// 배열을 분할하는 함수
int partition(int list[], int left, int right) {
int pivot, temp;
int low, high;
low = left;
high = right + 1;
pivot = list[left]; // 피벗을 배열의 첫 번째 요소로 설정
do {
do // 왼쪽에서 피벗보다 큰 값 찾기
low++;
while (list[low] < pivot);
do // 오른쪽에서 피벗보다 작은 값 찾기
high--;
while (list[high] > pivot);
if (low < high) // low와 high가 교차하지 않았다면 값 교환
SWAP(list[low], list[high], temp);
} while (low < high);
// 피벗과 high 위치의 값 교환
SWAP(list[left], list[high], temp);
return high; // 새로운 피벗 위치 반환
}
// 퀵 정렬 함수
void quick_sort(int list[], int left, int right) {
if (left < right) {
int q = partition(list, left, right); // 배열을 분할하여 피벗 위치 찾기
quick_sort(list, left, q - 1); // 피벗 왼쪽 부분 정렬
quick_sort(list, q + 1, right); // 피벗 오른쪽 부분 정렬
}
}
int main(void) {
int i;
n = MAX_SIZE; // 배열 크기 설정
srand(time(NULL)); // 난수 생성을 위한 시드 설정
// 난수 생성 및 출력
for (i = 0; i < n; i++)
list[i] = rand() % 100;
quick_sort(list, 0, n - 1); // 퀵 정렬 호출
// 정렬된 배열 출력
for (i = 0; i < n; i++)
printf("%d ", list[i]);
printf("\n");
return 0;
}12.9 기수 정렬
- 입력 데이터에 대해 비교 연산을 실행하지 않고 정렬하는 기법
- 기수(radix)란 숫자의 자리수이다.
- 42는 4와 2의 두개의 자릿수를 가지고 있다.
- 기수 정렬은 자릿수의 값에 따라서 정렬한다.


더보기
#include <stdio.h>
#include <stdlib.h>
#define MAX_QUEUE_SIZE 100
typedef int element;
typedef struct { // 큐 타입
element data[MAX_QUEUE_SIZE];
int front, rear;
} QueueType;
// 오류 함수
void error(char *message)
{
fprintf(stderr, "%s\n", message);
exit(1);
}
// 공백 상태 검출 함수
void init_queue(QueueType *q)
{
q->front = q->rear = 0;
}
// 공백 상태 검출 함수
int is_empty(QueueType *q)
{
return (q->front == q->rear);
}
// 포화 상태 검출 함수
int is_full(QueueType *q)
{
return ((q->rear + 1) % MAX_QUEUE_SIZE == q->front);
}
// 삽입 함수
void enqueue(QueueType *q, element item)
{
if (is_full(q))
error("큐가 포화상태입니다");
q->rear = (q->rear + 1) % MAX_QUEUE_SIZE;
q->data[q->rear] = item;
}
// 삭제 함수
element dequeue(QueueType *q)
{
if (is_empty(q))
error("큐가 공백상태입니다");
q->front = (q->front + 1) % MAX_QUEUE_SIZE;
return q->data[q->front];
}
#define BUCKETS 10
#define DIGITS 4
void radix_sort(int list[], int n)
{
int i, b, d, factor = 1;
QueueType queues[BUCKETS];
for (b = 0; b<BUCKETS; b++) init_queue(&queues[b]); // 큐들의 초기화
for (d = 0; d<DIGITS; d++) {
for (i = 0; i<n; i++) // 데이터들을 자리수에 따라 큐에 삽입
enqueue(&queues[(list[i] / factor) % 10], list[i]);
for (b = i = 0; b<BUCKETS; b++) // 버킷에서 꺼내어 list로 합친다.
while (!is_empty(&queues[b]))
list[i++] = dequeue(&queues[b]);
factor *= 10; // 그 다음 자리수로 간다.
}
}
#define SIZE 10
int main(void)
{
int list[SIZE];
srand(time(NULL));
for (int i = 0; i<SIZE; i++) // 난수 생성 및 출력
list[i] = rand() % 100;
radix_sort(list, SIZE); // 기수정렬 호출
for (int i = 0; i<SIZE; i++)
printf("%d ", list[i]);
printf("\n");
return 0;
}- 0~9까지의 Bucket(Queue)를 준비
- 모든 데이터에 대하여 가장 낮은 자릿수에 해당하는 Bucket에 차례대로 데이터를 입력
- 0부터 차례대로 Bucket에서 데이터를 다시 가져온다.
- 가장 높은 자릿수를 기준으로 자릿수를 높여가며 반복
728x90
반응형
'C언어로 쉽게 풀어쓴 자료구조' 카테고리의 다른 글
| [C언어로 쉽게 풀어쓴 자료구조] 11장 그래프 Ⅱ (0) | 2025.01.30 |
|---|---|
| [C언어로 쉽게 풀어쓴 자료구조] 10장 그래프 Ⅰ (1) | 2025.01.14 |
| [C언어로 쉽게 풀어쓴 자료구조] 9장 우선순위 큐 (0) | 2025.01.02 |
| [C언어로 쉽게 풀어쓴 자료구조] 8장 트리 - Ⅱ (0) | 2024.12.12 |
| [C언어로 쉽게 풀어쓴 자료구조] 8장 트리 - Ⅰ (0) | 2024.11.24 |